
Mathematics-Online lexicon:
|
|
[home] [lexicon] [problems] [tests] [courses] [auxiliaries] [notes] [staff] |
|
|
Mathematics-Online lexicon: | ||
Codes and Linear Codes | ||
| A B C D E F G H I J K L M N O P Q R S T U V W X Y Z | overview |
Codes.
Let
![]() be a finite set with
be a finite set with ![]() elements, which is called
alphabet. A code
elements, which is called
alphabet. A code
![]() of
length
of
length
![]() is a subset of
is a subset of
![]() . The code words are written
as
. The code words are written
as ![]() - tuples
- tuples
The information rate of
![]() is defined as
is defined as
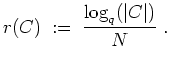
For
![]() the Hamming distance of
the Hamming distance of
![]() and
and
![]() is
is
A minimal distance decoder (MDD) gives to each
![]() a
word
a
word
![]() , which has minimal Hamming distance to
, which has minimal Hamming distance to ![]() A MDD is
therefore a function
A MDD is
therefore a function
![]() with
with
Two codes
![]() and
and
![]() are called equivalent provided there is
a permutation
are called equivalent provided there is
a permutation
![]() of
of
![]() such that
such that
Task of coding theory is to find codes with big minimal distance and big information rate.
Linear Codes.
Let
![]() be a finite field and
be a finite field and
![]() the vector space of dimension
the vector space of dimension
![]() over
over
![]() . A subspace
. A subspace
![]() of
of
![]() is called a linear code.
If
is called a linear code.
If
![]() is a basis of
is a basis of
![]() , written as row vectors,then
the matrix
, written as row vectors,then
the matrix
![]() with the rows
with the rows
![]() is called
a generator matrix of
is called
a generator matrix of
![]() .
.
A linear code
![]() of dimension
of dimension
![]() has the information rate
has the information rate
![]() . If its minimal distance is
. If its minimal distance is
![]() , then the code is
called a
, then the code is
called a
![]() -Code.
-Code.
The minimal distance of a linear code coincides with the minimal number of non-zero entries of a code word which is different from the zero vector.
Let ![]() be a finite field and let
be a finite field and let
![]() be a code. Assume that
any two distinct words of
be a code. Assume that
any two distinct words of ![]() have distance at least
have distance at least ![]() , i.e.
, i.e.
![]() Suppose that
Suppose that ![]() differs from a code word
differs from a code word ![]() by
by ![]() coordinates (if
coordinates (if ![]() is the word obtained after transmission of
is the word obtained after transmission of ![]() then one
says the transmission had
then one
says the transmission had ![]() errors ). Because
errors ). Because
![]() all other
code words differ from
all other
code words differ from ![]() by more than
by more than ![]() coordinates. So we have a unique
candidate which code word
coordinates. So we have a unique
candidate which code word ![]() should be if it is obtained after transmission
of some code word. Note that the correction of
should be if it is obtained after transmission
of some code word. Note that the correction of ![]() to this candidate is correct
provided the transmission had no more than
to this candidate is correct
provided the transmission had no more than ![]() errors. This leads to the
following definition.
errors. This leads to the
following definition.
An ![]() - error correcting code is a subset of
- error correcting code is a subset of ![]() with the property
with the property
Let
![]() be a linear code of dimension
be a linear code of dimension
![]() , then
, then
![]() is equivalent
to a linear code with a generator matrix
is equivalent
to a linear code with a generator matrix
![]() , where
, where
![]() denotes the identity matrix.
denotes the identity matrix.
For a linear code
![]() with generator matrix
with generator matrix
![]() a check matrix is given by
a check matrix is given by
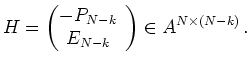
Each matrix
![]() with the properties
with the properties
If
![]() is a code word and
is a code word and
![]() the difference between the
word obtained after transmission and the original code word, then the
multiplication with the check matrix
the difference between the
word obtained after transmission and the original code word, then the
multiplication with the check matrix
A MDD for a linear code
![]() is defined by
is defined by
![]() with
with
![]() where
where
![]() depending on
depending on
![]() is chosen such that
is chosen such that
![]() and such that
and such that
![]() .
.
(If
![]() is greater equal than the number of
transmission errors (inside a transmitted code word)
then one obtains by
is greater equal than the number of
transmission errors (inside a transmitted code word)
then one obtains by
![]() as above
as above
![]() .)
.)
Binary Hamming Codes.
A binary Hamming Code of length
![]() (with
(with
![]() ) is
determined by a check matrix
) is
determined by a check matrix
![]() with the property that
its row vectors are just all vectors
of
with the property that
its row vectors are just all vectors
of
![]() . Hamming codes are
. Hamming codes are
![]() -Codes.
The advantage for the practice is the simple error correction.
-Codes.
The advantage for the practice is the simple error correction.
For binary Hamming codes and
![]() the syndrom
the syndrom
![]() is at most at one position different from
zero.
The (unique) MDD is given by
is at most at one position different from
zero.
The (unique) MDD is given by

Examples:
| automatically generated 7/ 7/2005 |